

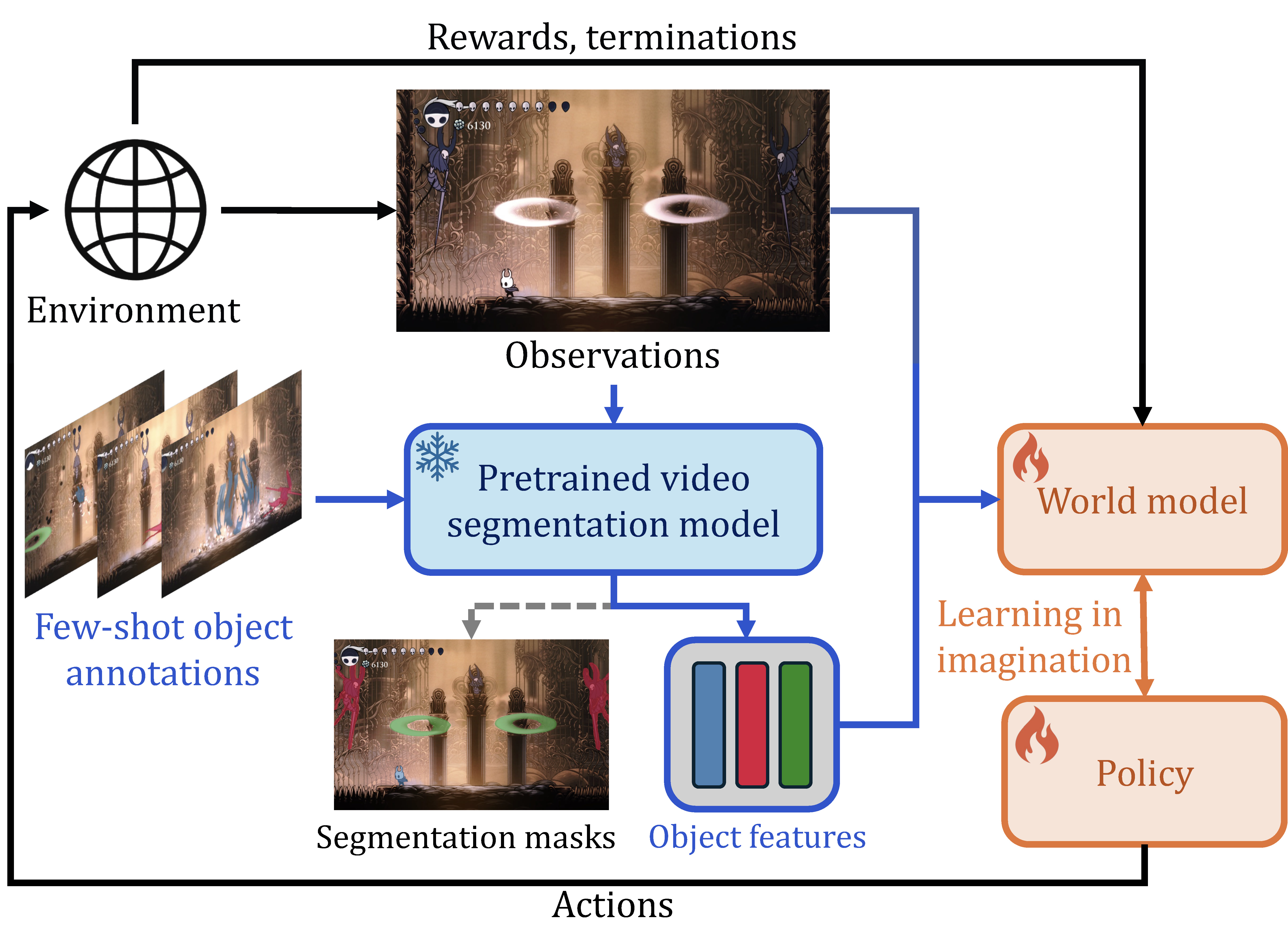
Left: STORM accurately reconstructs large background areas (blue) but overlooks the small, critical player and boss characters (orange), hindering policy learning. Right: Overview of the proposed OC-STORM framework.
While deep reinforcement learning (RL) from pixels has achieved remarkable success, its sample inefficiency remains a critical limitation for real-world applications. Model-based RL (MBRL) addresses this by learning a world model to generate simulated experience, but standard approaches that rely on pixel-level reconstruction losses often fail to capture small, task-critical objects in complex, dynamic scenes. We posit that an object-centric (OC) representation can direct model capacity toward semantically meaningful entities, improving dynamics prediction and sample efficiency. In this work, we introduce OC-STORM, an object-centric MBRL framework that enhances a learned world model with object representations extracted by a pretrained segmentation network. By conditioning on a minimal number of annotated frames, OC-STORM learns to track decision-relevant object dynamics and inter-object interactions without extensive labeling or access to privileged information. Empirical results demonstrate that OC-STORM significantly outperforms the STORM baseline on the Atari 100k benchmark and achieves state-of-the-art sample efficiency on challenging boss fights in the visually complex game Hollow Knight. Our findings underscore the potential of integrating OC priors into MBRL for complex visual domains.
Defeating Mantis Lords with no spells
Mage Lord
Hornet
God Tamer
We use Cutie [Cheng et al., 2023] as our object extractor. Cutie is a retrieval-based video object segmentation model that maintains effective tracking in dynamic and visually-complex scenes over long sequences. While the generated masks may contain noise or "burrs," the tracking remains semantically accurate. By utilizing high-level semantic object features for control, we mitigate the impact of mask noise on policy learning.
We provide standard segmentation masks as prompts for the algorithm. Annotating each mask requires less than one minute. Following the Cutie pipeline, we use a semi-automatic segmentation method based on RITM [Sofiiuk et al., 2021], where masks are generated efficiently by iteratively adding positive and negative anchors. This process yields fast and accurate annotations. In practice, producing 6 annotated frames per environment for Atari tasks and 12 annotated frames per boss for Hollow Knight takes approximately 10-15 minutes.
@inproceedings{
zhang2026objectcentric,
title={Object-Centric World Models from Few-Shot Annotations for Sample-Efficient Reinforcement Learning},
author={Weipu Zhang and Adam Jelley and Trevor McInroe and Amos Storkey and Gang Wang},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=qmEyJadwHA}
}